Concepts
Portworx Backup (PX-Backup) is a Kubernetes backup solution that allows you to back up and restore applications, KubeVirt Virtual Machines (VMs) and their data across multiple clusters. Portworx Backup works with Portworx Central (a web console, that centralizes various features or products including Portworx Backup into a single user interface), allowing administrators or other users to manage backups and restores of multiple Kubernetes clusters from a single user interface. Under this principle of multi-tenancy, authorized users connect through authorization providers to create and manage backups for clusters and applications for which they have permissions (without reaching out the administrator). Portworx Backup maintains a repository of available application backups and restores them to any destination cluster that a user has access to. Portworx Backup communicates with backup locations on regular-basis to check for the availability of new backups.
Portworx Backup architecture
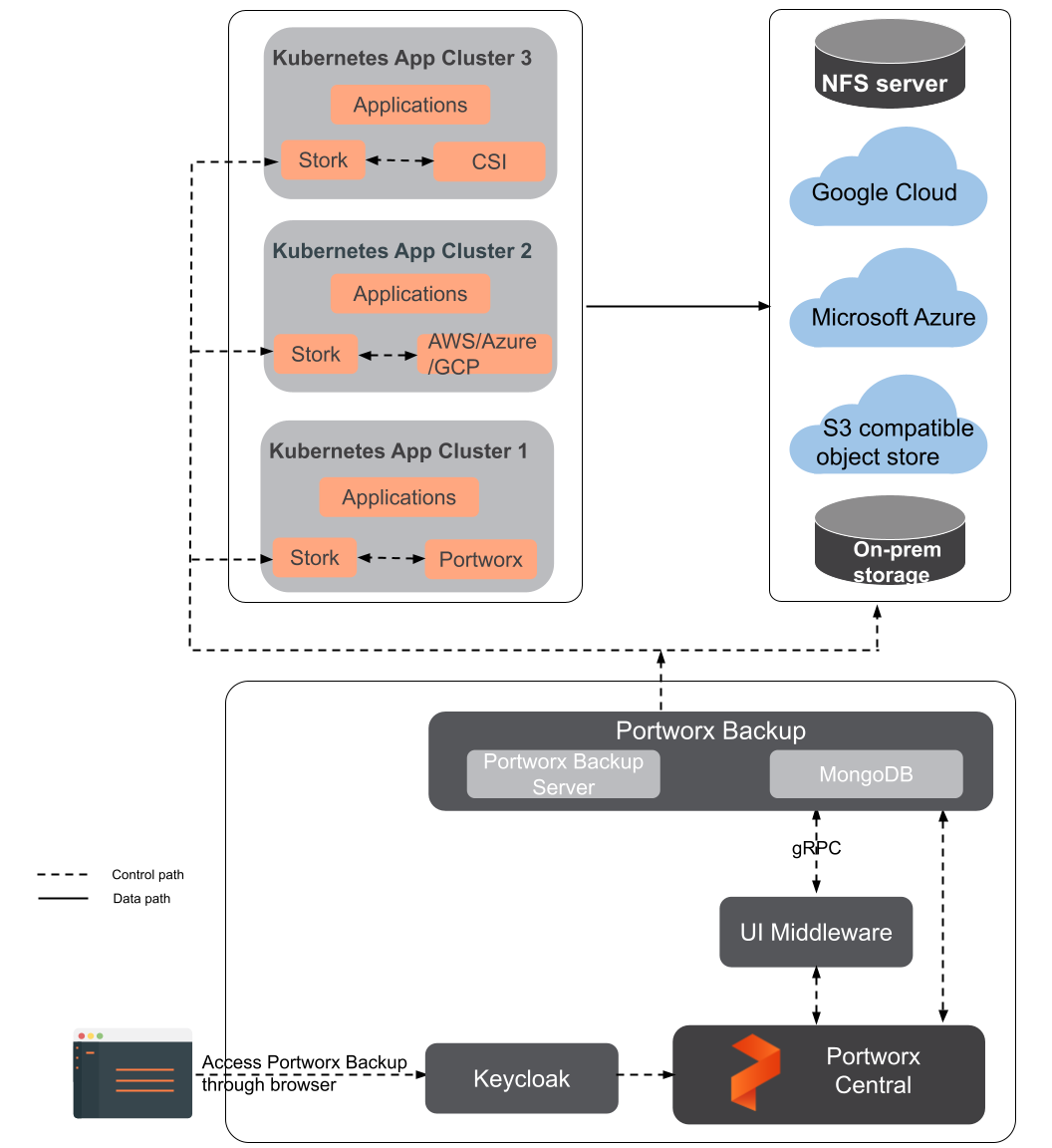
Understand how Portworx Backup works
Portworx Backup is compatible with any Kubernetes cluster, including managed and cloud deployments, and does not require Portworx Enterprise to be installed. Portworx Backup integrates with the following major categories of storage providers:
- AWS S3
- S3 compatible object store
- Azure
- NFS
- EFS
- GCP Filestore
- Azure file share
Portworx Backup supports taking backup on the following backup targets:
| Block storage (Data being backed up from) | File storage (Data being backed up from) |
|---|---|
|
|
Portworx Backup can back up Kubernetes native resources:
- ClusterRole
- ClusterRoleBinding
- ConfigMap
- Custom CRDs (via a CRD registration process)
- Custom resources
- DaemonSet
- Deployment
- Ingress
- Persistent Volume (PV)
- Persistent Volume Claim (PVC)
- Role
- RoleBinding
- Service
- Secret
- ServiceAccount
- StatefulSet
The Portworx Backup web console displays a platform-dependent list of resources it can back up for each type of cluster. Additionally, even for the same platform, the resources list depends on the applications of the namespace.
Portworx Backup provides namespace and label selectors, allowing you to create granular backups of the application you want. You can back up an entire namespace, or you can use label selectors to select only certain resources to back up. This selection method also helps preserve associated configuration and pod data, ensuring that your backups work properly once restored. For example, Portworx Backup can back up a MySQL deployment containing pods, PVCs, and volumes tagged with an app = mysql label. You can apply the labels for your namespaces, resources and their backups with a key-value pair using the CLI and with Portworx Backup user interface you can filter them when needed at a later point in time to create a backup. Given this system, Portworx Backup can back up stateful applications as easily as stateless ones. For more information on how labels work, refer to Labels in Portworx Backup.
You can schedule backups by creating an independent schedule policy that defines when backups must run and how many rolling copies they keep, and you can associate this schedule policy with as many backups as you want.
Portworx Backup helps you to eliminate manual preparation tasks and lets you minimize the interruptions to your cluster associated with backup tasks by creating backup rules that run before and after backups are taken. As with schedule policies, you can associate rules with multiple backups.
The following topics help you to learn more on Portworx Backup:
📄️ Components
Learn about the various components of Portworx Backup
📄️ Stork
Learn about Stork and its role in backup and restore
📄️ Web console
You can interact with Portworx Backup through a central user interface called Portworx Backup web console. From here, you can: